
ArrayList и производительность массивов в Powershell
Powershell — язык весьма великодушный к программистам, почти всё в нём делается легко, интуитивно, и не требует особой подготовки и продумывания от автора кода. Однако, при выходе на объемные задачи начинают выстреливать некоторые вещи, которые для удобства изначально выполнены неэффективно.
По одной из задач мне требовалось обрабатывать большие объемы данных (сотни тысяч и миллионы строк таблиц). На тестовых множествах всё работало хорошо, но на прод данных скрипт начинал работать непозволительно долго. Я провел профилирование и выяснил, что с ростом количества данных всё больше времени (с нелинейным ростом) начинает занимать операция добавления элемента в архив.
$array = $array + $newElement — что может быть интуитивней? Оказалось, массивы в Powerhsell это имутабельные объекты, и поэтому предыдущий код фактически создает новый неизменяемый объект из всех элементов предыдущего массива и одного нового. Конечно, на больших объемах массивов такая операция будет занимать всё больше времени, и нелинейный рост вполне объясним. Этой неэффективности лишен специальный тип данных ArrayList — это тот же массив, разве что элементы добавлять самым очевидным способом через «плюс» в него нельзя.
Вот код, на котором я проверил время работы цикла из добавления N случайных строк к массивам в умолчальном варианте и варианте ArrayList
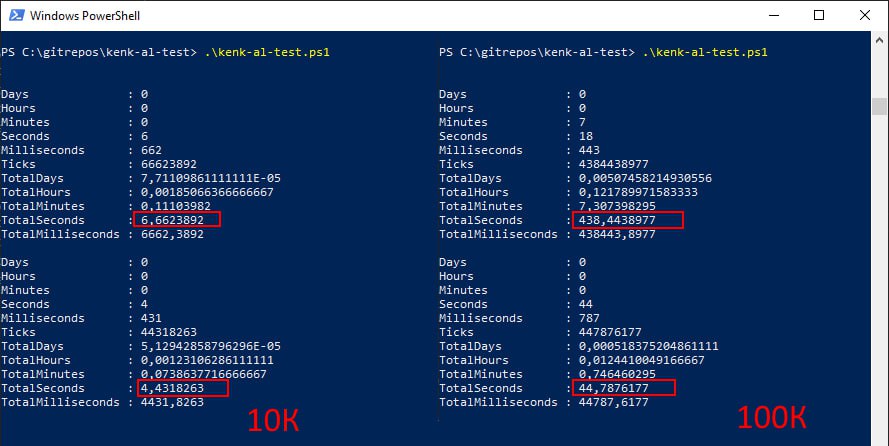
На 10 тысячах операций результаты примерно похожи — отличаются в десятки процентов. Но уже на сотне тысяч разница — на порядок. При этом время работы через ArrayList растет линейно вместе с количеством циклов, а у классических массивов — экспоненциально
Вот такие тонкости вскрываются спустя годы работы с языком. С другой стороны, это хорошо характеризует его в положительном плане — сколько за это времени гигабайт csvшек и джейсонов было перелопачено без этих ваших ArrayList?!